背景
之前在用 html-to-image 实现页面截图功能的时候(具体见 html-to-image 页面截图的实践和踩坑记录),发现在字体文件很多的页面里截图生成 SVG 格式的图片非常大,生成图片基本都在 10 MB 以上,这导致截图 + 上传到 CDN 的耗时基本都在 20 秒以上,旧一些的型号甚至需要 60 秒以上。
阅读 html-to-image 的源码和翻阅社区的相关 issue 之后,发现是 html-to-image 会将页面内的字体文件全量转换成 base64 并嵌入到生成的图片里,导致生成图片文件的过程非常耗时,而生成的图片随便都是 10MB 起步的大小,也直接导致了图像上传到 CDN 非常慢。
现状分析
因为 html-to-image 提供了 fontEmbedCSS 这个属性字段,让开发者自行处理字体的嵌入逻辑,因此如何最大程度降低字体文件的大小成为了解决问题的关键。
于是便有了此文的思路:读取截图页面上的全部文本,并按照文本对应的字体样式进行归类,然后在 Worker 线程根据文本将字体文件对应的字符集按需切割出来,并重新生成轻量的字体文件。而这个思路的核心点是如何在 Worker 线程里解析和按需切割字体。
通过一番的搜索和调研,找到 opentype.js 这个开源库( 仓库地址 )可以在浏览器环境和 Worker 线程中解析/切割字体文件的功能。
实现原理
字体文件( 如:xxx.ttf )是版权信息、字形表、字符映射表等一系列字体数据的二进制封装文件,因此可以将字体文件转换成浏览器可以解析的 ArrayBuffer 格式的数据,然后根据字体的解析规则读取出字体文件的每个文字对应的字形、字符等封装规则。
打个比较容易理解的比喻,我们平时使用到的字体文件实际上是一个封装好的字体数据库,这个字体数据库里有几十张与字体、字形相关的数据表,而 opentype.js 则类似于 Navicat ,是读取字体数据库的工具。
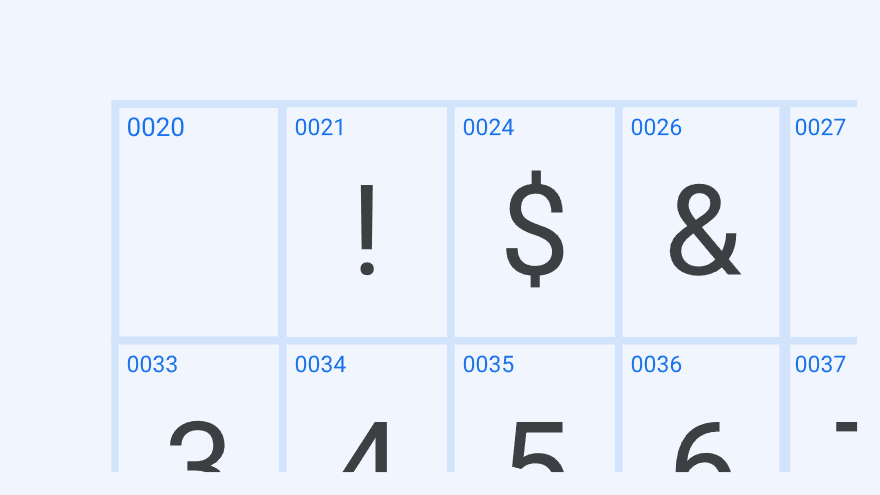
从 opentype.js 的代码设计思路来看,解析字体的流程有几个比较重要的步骤:
- 读取字体数据的前 4 个字节,确定字体的文件格式( ttf / otf / woff / woff2 )及与其对应的解析方式
- 解析字体文件中的表目录,获取字体文件中表的数量和每个表的元数据
- 按序逐个解析表信息,每个表存储了字体的不同信息
- 字形表:主要存储字体的字形,即字符的形状
- 字符映射表:定义字符编码与字形索引之间的映射关系
- 其他表:如包含每个字形的字形宽度和左边距的水平度量表、字体的头部信息表等
- 根据解析出来的数据创建
Font实例,这个实例包含了字体的所有信息,如字体名称、字形数据等
在解析完字体之后,便可以根据文本内容从 Font 实例中取出对应的字符、字形、度量等配置,然后重新生成新的字体实例。
字体解析
opentype.js 提供 parse 方法解析 ttf / otf / woff 这几个格式的字体文件,暂时不支持 woff2 格式的字体文件。
import { parse } from 'opentype.js';
import { decompress } from 'woff2-encoder';
/**
* 加载字体资源到本地
*/
async function loadFont(fontUrl: string) {
const matched = /\.([^./]*?)$/g.exec(fontUrl) || [];
const isWoff2 = (matched[0] || '').toLowerCase() === '.woff2';
// 请求字体文件的二进制流
const fontBuffer = await fetch(fontUrl).then(res => res.arrayBuffer());
// NOTE:
// Woff2 格式的字体使用了新的压缩算法,使得字体文件的体积小 30% 以上
// 因此在读取 woff2 的字体时需要先对字体解压,才能继续进行解析操作
if (isWoff2) {
const output = await decompress(fontBuffer);
return parse(output.buffer);
}
return parse(fontBuffer);
}2024-01-25 Update
对于 woff2 字体,可以通过 Google 提供的解压工具将 woff2 格式的字体解压为 woff 格式,但因为用的是 C++ 语言开发的,无法直接在浏览器使用。好在社区内也有提供编译后成 wasm 版本的解压库,比如 wawoff2、 woff2-encoder 。
字体编码
因为 opentype.js 是国外开源团队实现的,所以没有针对中文的编码转换逻辑。因此在字体切割之前,需要将中文字符按照一定规则编码为 unicode 格式;除此之外,还需要额外处理一些阿拉伯数字、特殊中文符号的字符转换逻辑。
// 字体替换字符集
const DEFAULT_UNICODE_MAPS: Record<string, string> = {
0: 'zero',
1: 'one',
2: 'two',
3: 'three',
4: 'four',
5: 'five',
6: 'six',
7: 'seven',
8: 'eight',
9: 'nine',
};
/**
* 字符编码为 unicode
*/
function strToUnicode(fontString: string) {
// 必须对传入的字体内容去重、去空格
const chars = fontString.split('').reduce<string[]>((str, char) => {
if (!!char.trim() && !str.includes(char)) {
str.push(char);
}
return str;
}, []);
return [
// 默认字符,用来处理空格/无效字符的情况
'.notdef',
...chars.map(char => {
// 将文字内容转化为 unicode,如:你 -> %u4F60 -> \u4f60
const escapeFont = escape(char).replace(/^%u/, '\\u');
// 是否是汉字
const isChinese = escapeFont.includes('\\u');
// 取出汉字码,如 \u4f60 -> 4F60
const fontUnicode = escapeFont.replace(/\\u/g, '');
// 如果是数字/英文符号,需要单独转换为英语进行解析,字母不需要解析
const fontCode = DEFAULT_UNICODE_MAPS[fontUnicode] || fontUnicode;
// 如果是汉字(含中文符号),则会解析成 uni{UNICODES} 的格式
return `${isChinese ? 'uni' : ''}${
isChinese ? fontUnicode : unescape(fontCode)
}`;
}),
];
}字体切割
在处理好字体编码的问题之后,就可以通过 opentype.js 提供的方法取出对应文本的字形创建新的字体类,然后导出为新字体的二进制数据,按照自己的需求转换为对应格式即可。我因为要在 SVG 中嵌入字体编码,所以转换的是 base64 格式。
/**
* 字体切割
*/
async function splitFont(fontUrl: string, fontContent: string) {
const font = await loadFont(fontUrl);
const {
glyphs,
ascender,
descender,
unitsPerEm,
names: { fontFamily, fontSubfamily },
} = font;
// 字体去重编码
const fontUnicode = strToUnicode(fontContent);
// 从字形集中取出对应文字的字形
const fontGlyphs = fontUnicode.reduce<Glyph[]>((fontGlyphs, unicode) => {
const index = font.charToGlyphIndex(unicode);
if (index > -1) {
const glyph = glyphs.get(index);
fontGlyphs.push(glyph);
}
return fontGlyphs;
}, []);
// 重新生成新的字体实例
const fontCtor = new Font({
glyphs: fontGlyphs,
ascender,
descender,
styleName: fontSubfamily.en || fontSubfamily.zh,
familyName: fontFamily.en || fontFamily.zh,
unitsPerEm,
});
// 导出新字体的 ArrayBuffer
return fontCtor.toArrayBuffer();
}完整代码
以下是在浏览器环境裁剪压缩字体的完整逻辑,在 Worker 线程只需要增加 Worker 环境下的监听事件的相关语句即可。
import { decompress } from 'woff2-encoder';
import { parse, Font, Glyph } from 'opentype.js';
// 字体替换字符集
const DEFAULT_UNICODE_MAPS: Record<string, string> = {
0: 'zero',
1: 'one',
2: 'two',
3: 'three',
4: 'four',
5: 'five',
6: 'six',
7: 'seven',
8: 'eight',
9: 'nine',
};
/**
* 字符编码为 unicode
*/
function strToUnicode(fontString: string) {
// 必须对传入的字体内容去重、去空格
const chars = fontString.split('').reduce<string[]>((str, char) => {
if (!!char.trim() && !str.includes(char)) {
str.push(char);
}
return str;
}, []);
return [
// 默认字符,用来处理空格/无效字符的情况
'.notdef',
...chars.map(char => {
// 将文字内容转化为 unicode,如:你 -> %u4F60 -> \u4f60
const escapeFont = escape(char).replace(/^%u/, '\\u');
// 是否是汉字
const isChinese = escapeFont.includes('\\u');
// 取出汉字码,如 \u4f60 -> 4F60
const fontUnicode = escapeFont.replace(/\\u/g, '');
// 如果是数字/英文符号,需要单独转换为英语进行解析,字母不需要解析
const fontCode = DEFAULT_UNICODE_MAPS[fontUnicode] || fontUnicode;
// 如果是汉字(含中文符号),则会解析成 uni{UNICODES} 的格式
return `${isChinese ? 'uni' : ''}${
isChinese ? fontUnicode : unescape(fontCode)
}`;
}),
];
}
/**
* 加载字体资源到本地
*/
async function loadFont(fontUrl: string) {
const matched = /\.([^./]*?)$/g.exec(fontUrl) || [];
const isWoff2 = (matched[0] || '').toLowerCase() === '.woff2';
// 请求字体文件的二进制流
const fontBuffer = await fetch(fontUrl).then(res => res.arrayBuffer());
// NOTE:
// Woff2 格式的字体使用了新的压缩算法,使得字体文件的体积小 30% 以上
// 因此在读取 woff2 的字体时需要先对字体解压,才能继续进行解析操作
if (isWoff2) {
const output = await decompress(fontBuffer);
return parse(output.buffer);
}
return parse(fontBuffer);
}
/**
* 字体切割
*/
async function splitFont(fontUrl: string, fontContent: string) {
const font = await loadFont(fontUrl);
const {
glyphs,
ascender,
descender,
unitsPerEm,
names: { fontFamily, fontSubfamily },
} = font;
// 字体去重编码
const fontUnicode = strToUnicode(fontContent);
// 从字形集中取出对应文字的字形
const fontGlyphs = fontUnicode.reduce<Glyph[]>((fontGlyphs, unicode) => {
const index = font.charToGlyphIndex(unicode);
if (index > -1) {
const glyph = glyphs.get(index);
fontGlyphs.push(glyph);
}
return fontGlyphs;
}, []);
// 重新生成新的字体实例
const fontCtor = new Font({
glyphs: fontGlyphs,
ascender,
descender,
styleName: fontSubfamily.en || fontSubfamily.zh,
familyName: fontFamily.en || fontFamily.zh,
unitsPerEm,
});
// 导出新字体的 ArrayBuffer
return fontCtor.toArrayBuffer();
}
/**
* 转换为 base64
*/
function bufferToBase64(buffer: ArrayBuffer) {
const bytes = new Uint8Array(buffer);
const binary = bytes.reduce((binary, byte) => {
binary += String.fromCharCode(byte);
return binary;
}, '');
// 保证在 Worker 线程中不报错
if (
typeof WorkerGlobalScope !== 'undefined' &&
self instanceof WorkerGlobalScope
) {
return self.btoa(binary);
}
return window.btoa(binary);
}
/**
* 根据文本内容输出字体内容
*/
async function fontCompress(fontUrl: string, fontContent: string) {
const buffer = await splitFont(fontUrl, fontContent || '');
return `data:font/woff;base64,${bufferToBase64(buffer)}`;
}
export default fontCompress;其他
比较有意思的是,我们常用的图标文件也可以算作字体文件的一种,也就是说可以通过 opentype.js 读取图标文件的图标资源。
基于这个思路,我在工作之余通过 tauri + opentype.js 实现了 Iconfont Preview 这款图标查看工具,可以方便地查看本地和远程的图标文件。