最近闲着没事折腾了一阵微信小程序的云开发,也了解了一些关于 Serverless 无服务器的相关概念,对里面云函数是如何在服务器运行这个问题产生了浓厚的兴趣。
我在微信小程序的文档里提到微信云函数是腾讯云提供的服务,于是到腾讯云网站翻了一下云函数相关的文档( 点击此处 ),找到了一些云函数实现的实现原理。
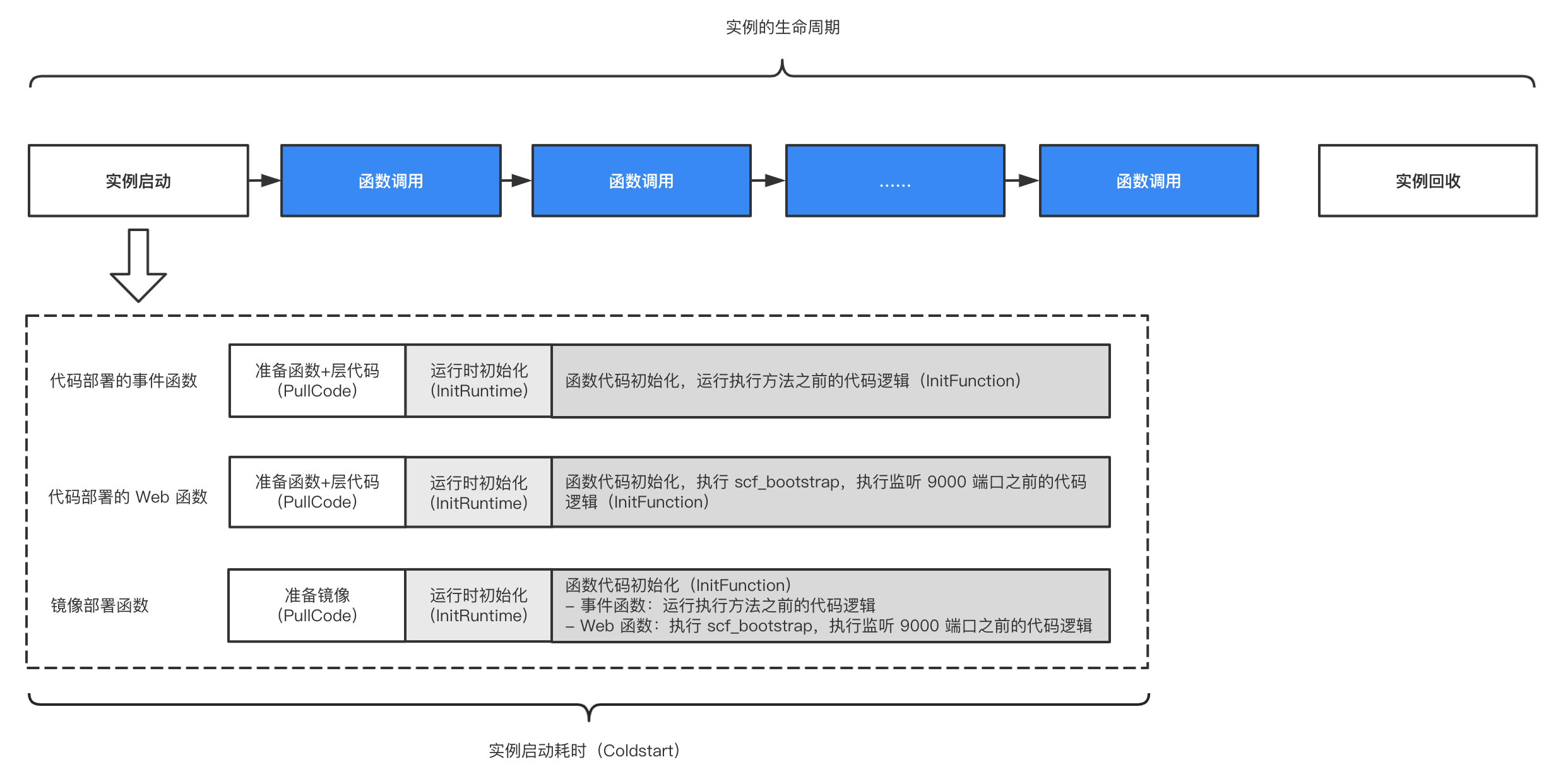
在梳理一些文档之后,大致了解云函数的运行流程:
- 将开发者在本地编写的云函数编译成 js 文件之后上传到 CDN 存储
- 在调用云函数时,拉取 CDN 上的代码到服务器的临时目录上准备执行
- 创建云函数的运行容器( 可能是虚拟机,也可能是其他 ),导入云函数的源码执行
- 得到执行结果后返回给调用方完成逻辑闭环
最重要的一步是第 3 步,但是并没有在文档里找到云函数运行容器是如何实现的,但我对这部分也最感兴趣,所以结合了一些对云函数的了解就开始了自己的胡乱猜测。
vm 虚拟机方案
最先想到的方案是使用 Node.js 里的 vm 虚拟机来实现,通过 fetch 方法直接拉取在 CDN 上的代码到虚拟机中执行。
import * as vm from 'vm';
/**
* 运行云函数
*/
async function runCloudFunction(sourceCode: string, args: Record<string, any>) {
// 在虚拟机中解析云函数的源码
const script = new vm.Script(sourceCode);
// 执行云函数
const cloudFn = await script.runInThisContext();
const fnResult = await cloudFn(args);
// 返回云函数的执行结果
return fnResult;
}
/**
* 执行云函数
*/
async function invokeCloudFunction(
fnName: string,
fnArgs: Record<string, any>
) {
try {
const fnUrl = `https://cdn.xxx.com/xxx/assets/${fnName}/index.js`;
const fnCode = await fetch(fnUrl).then(res => res.text());
const fnResult = await runCloudFunction(fnCode, fnArgs);
return { success: true, message: 'success', result: fnResult };
} catch (e) {
return { success: false, message: e.message, result: null };
}
}
(async function () {
// DEMO:
// HelloWorld → exports.main = () => 'HelloWorld';
const result = await invokeCloudFunction('HelloWorld');
// result → { success: true, message: 'success', result: 'HelloWorld' }
console.log('result', result);
})();实现之后发现虚拟机的方案存在很多的问题,虚拟机只能解决单个代码文件的运行问题,但是无法解决整个云函数项目的目录结构、依赖管理、模块引入等一系列的问题。
以模块引入为例:
// 引入 npm 开源库
const log4js = require('log4js');
// 引入数据库操作模型
const User = require('../models/user');
// 日志打印
const logger = log4js.getLogger();
exports.main = async function () {
const allUsers = await User.findMany();
logger.debug('User.allUsers = ', allUsers);
return allUsers;
};为了解决上面模块引入的逻辑,需要在代码里处理不同的模块导入规则,还必须考虑沙箱逃逸一类的安全性问题。如果用社区目前比较主流的虚拟机方案 isolated-vm 来解决代码执行的安全性问题,则需要解决大量无法拷贝的数据结构( 如:函数、方法 )如何传递的问题。
import * as vm from 'vm';
/**
* 运行云函数
*/
async function runCloudFunction(
files: Record<string, string>,
entryFile: string,
args: Record<string, any>
) {
// 在虚拟机中解析云函数的源码
const script = new vm.Script(files[entryFile] || '');
// 在代码的上下文注入 Node.js 的全局变量和方法
const context = vm.createContext({
module,
console,
process,
exports,
__dirname: __dirname,
__filename: __filename,
// 手动处理
require: (moduleOrFile: string) => {
switch (moduleOrFile) {
case 'wx-server-sdk': {
// 处理自定义引入的报名
return require('./wx-server-sdk');
}
case moduleOrFile.startWith('.'): {
// 处理内联引入的文件
// 处理场景: const User = require('../models/user')
const name = moduleOrFile.replace(/^\.\/+/, '/');
const code = files[name];
// 仅为讨论,该代码实际不可用
return new vm.Script(code);
}
default: {
// 处理导入的模块
// 处理场景: const lodash = require('lodash')
// if (CloudFunctionDependencies[moduleOrFile]) {
// return CloudFunctionDependencies[moduleOrFile];
// }
throw new Error(`require('${moduleOrFile}') is not defined.`);
}
}
},
});
// 执行云函数
const cloudFn = await script.runInContext(context); // [!code++]
const fnResult = await cloudFn(args);
// 返回云函数的执行结果
return fnResult;
}综合来看,vm 虚拟机方案只适合一些无依赖的单文件的业务场景,或者是云函数的代码经过特殊的编译处理,不需要处理文件引入、依赖处理这一类的逻辑。从微信这种体量的公司来考虑,vm 虚拟机方案并不适合线上环境,存在太多的问题需要解决。
Docker 容器方案
前文提到 vm 虚拟机方案只适合处理单文件的业务场景,那是否有一种虚拟机可以处理一整个项目文件的业务场景?
有的,那就是 Docker !但本文主要讨论的是如何在 Docker 环境运行云函数,因此不会讨论 Docker 的原理和功能。
在电脑上安装好 Docker 环境之后,Node.js 变可以通过 dockerode 这个开源库调用 Docker 的相关功能。
import Docker from 'dockerode';
// 创建 Docker 引用的实例
const docker = new Docker();
// 读取本地安装的 Docker 版本号
docker.version().then(version => {
// version → { Platform: { Name: 'Docker Desktop 4.6.0' } }
console.log('version', version);
});在解决 Node.js 环境中调用 Docker 能力的问题之后,如何在 Docker 容器中执行云函数这个问题解决起来就简单许多。由于 dockerode 支持通过 tar 文件的形式加载镜像,那我们可以在云函数编译上传这一步的时候,将每个云函数打包成下面这种目录结构的 tar 文件。
.
├── Dockerfile
├── package.json
└── src
├── hello-world.js # 云函数文件
└── index.js # 入口文件,用于处理云函数的调用和通信机制等相关逻辑然后可以根据自身的业务形态,动态生成 Dockerfile 和 package.json 两个文件,配置云函数所需要的运行环境。
# 使用 Node.js 官方镜像作为基础镜像
FROM node:latest
# 设置工作目录
WORKDIR /app
# 将当前目录下的所有文件复制到工作目录下
COPY . /app
# 安装依赖
RUN npm install
# 指定容器启动时执行的命令
CMD ["npm", "start"]{
"name": "cloud-function-runtime",
"author": "fei-hui",
"scripts": {
"start": "node ./src/index.js",
},
"dependencies": {
// 可根据配置动态生成依赖 → dependencies: [{ name: 'lodash', version: '1.0.0' }]
},
}考虑到云函数需要获取入参和返回执行结果给外部的 Node.js 环境,因此需要在云函数的入口文件 index.js 和外部的 Node.js 环境实现相关的通信机制,从而完成云函数调用的闭环。
const cloudFunction = require('./hello-world');
(async function () {
// 从环境变量取出注入的参数
const args = process.env.CLOUD_FUNCTION_PARAMS;
const result = await cloudFunction.main(args && JSON.parse(args));
// 将执行结果按照特定的格式打到日志中
process.stdout.write(
`[CLOUD_FUNCTION_RESULT] result=<%=${JSON.stringify(result)}=%>`
);
})();import fetch from 'node-fetch';
import Docker from 'dockerode';
// 创建 Docker 引用的实例
const docker = new Docker();
/**
* 执行云函数
*/
async function invokeCloudFunction(
fnName: string,
fnArgs: Record<string, any>
) {
// 从 CDN 加载源码
const fnUrl = `https://cdn.xxx.com/xxx/assets/${fnName}.tar`;
const fnCode = await fetch(fnUrl).then(res => res.body);
// 边界条件
if (!fnCode) return null;
// 镜像名字需唯一
const imageName = `cloud-function-image-${Math.random().toString(16).slice(2, 8)}`;
// 根据源码构建 Docker 镜像
const imageStream = await docker.buildImage(fnCode, { t: imageName });
// Docker 镜像构建日志输出到控制流
imageStream.pipe(process.stdout, { end: true });
// 等待 Docker 镜像构建完成,第一次运行会很慢
await new Promise((resolve, reject) => {
docker.modem.followProgress(imageStream, (error, result) =>
error ? reject(error) : resolve(result)
);
});
// 根据镜像里创建 Docker 容器
const container = await docker.createContainer({
Cmd: ['npm', 'start'], // 对应 package.json 的执行命令
Env: [`CLOUD_FUNCTION_PARAMS=${JSON.stringify(fnArgs)}`],
Image: imageName,
});
// 获取容器的日志输出
const output = await container.attach({
stream: true,
stdout: true,
stderr: true,
});
return new Promise(async (resolve, reject) => {
let target = null;
// 监听容器执行过程
output.on('data', (buffer: Buffer) => {
// 从输出的日志流中找到匹配的结果输出
const chunk = buffer.toString();
const matched =
chunk.match(/\[CLOUD_FUNCTION_RESULT\] result=<%=(.+?)=%>/) || [];
if (matched[1]) {
target = JSON.parse(matched[1]);
}
});
// 监听容器执行结束
output.on('end', () => resolve(target));
// 开始执行容器
await container.start();
// 等待容器执行完成
await container.wait();
// 执行完成后清理容器释放占用
await container.remove();
});
}对比 vm 虚拟机方案,Docker 容器方案的优势明显,也更适合在线上环境使用。但是也有许多不足,比如:第一次构建镜像时需要下载很多依赖,因此会非常慢,需要提前在服务器上提前备好对应的镜像依赖。
性能问题
不管是虚拟机还是动态创建 Docker 镜像,都是非常耗时的逻辑,但是虚拟机和 Docker 镜像常驻也需要占用大量的运行内存,当遇到流量高峰时,服务器可能会出现严重的性能问题。
无独有偶,微信云函数的官方文档( 常驻云函数 )里也明确说明了执行云函数存在一定的冷启动时长,猜测微信也是通过类似的方法来实现服务器调用云函数的逻辑。
云函数在处理请求之前,需要经历初始化的过程,会存在一定的冷启动时长。对于业务请求敏感的场景,可通过设置常驻云函数用以减少冷启动,快速响应请求。在设置常驻云函数后,系统会自动根据配置立刻创建云函数实例,用以“等待”请求的到来。系统不会主动收回该常驻云函数实例,若该实例闲置未处理请求时,将会根据闲置时长及数量等配置收取闲置费用。
目前来看没有什么比较好的性能优化策略,几种比较常见的优化策略本质上都是类似于负载均衡 + 微服务集群的模式,分散运行任务来降低单机器的运行压力。也许等 WebAssembly 的社区和相关的解决方案成熟之后,通过 WebAssembly 执行云函数应该能够提升运行的性能。
上一篇:如何在浏览器中在线编译代码